- Real Time Telematics Platform on MongoDB
- MongoDB Zero Shot Semantic Serach
- Building an AI-Powered Recommendation System using RAG, MongoDB, Ollama, and Gemini
- AI Database Features
- Understanding Agentic AI: The Shift from Passive Models to Autonomous Agents
- The AI Blockchain
- Model Context Protocol (MCP) vs Agent to Agent (A2A) Protocol
- Responsible AI
- Building a CI/CD Pipeline for Machine Learning Using AWS Services
- DeepSeek Architecture
- Machine Learning for Beginners. Your roadmap to success.
- The Machine Learning Algorithms List: Types and Use Cases
- Harnessing Machine Learning for Advanced A/V Analysis and Detection
- TensorFlow Lite vs PyTorch Mobile for On-Device Machine Learning
- Generative AI presents new opportunities for accelerating human achievement
- Unlocking the true potential of AI with UiPath business automation
- AI for good: Three principles to use AI at work responsibly
- Transforming healthcare document processing with AI
Building an AI-Powered Recommendation System using RAG, MongoDB, Ollama, and Gemini
Building an AI-Powered Movie Recommendation System using RAG, MongoDB, Ollama, and Gemini
In today’s AI-driven world, building intelligent applications requires more than just large language models. To deliver accurate and context-aware responses, modern systems combine data retrieval with generation — a technique known as Retrieval-Augmented Generation (RAG).
In this blog, we will explore how to build a Movie Recommendation Chat System using:
- MongoDB Atlas Vector Search
- Ollama (Embeddings)
- Google Gemini (LLM)
- Streamlit (UI)
The same can be replicated across any Database, LLM you like!
What is RAG?
Retrieval-Augmented Generation (RAG) is a hybrid approach where:
- Retriever fetches relevant data from a database
- Generator (LLM) uses that data to create meaningful responses
This ensures:
- More accurate answers
- Reduced hallucinations
- Better explainability
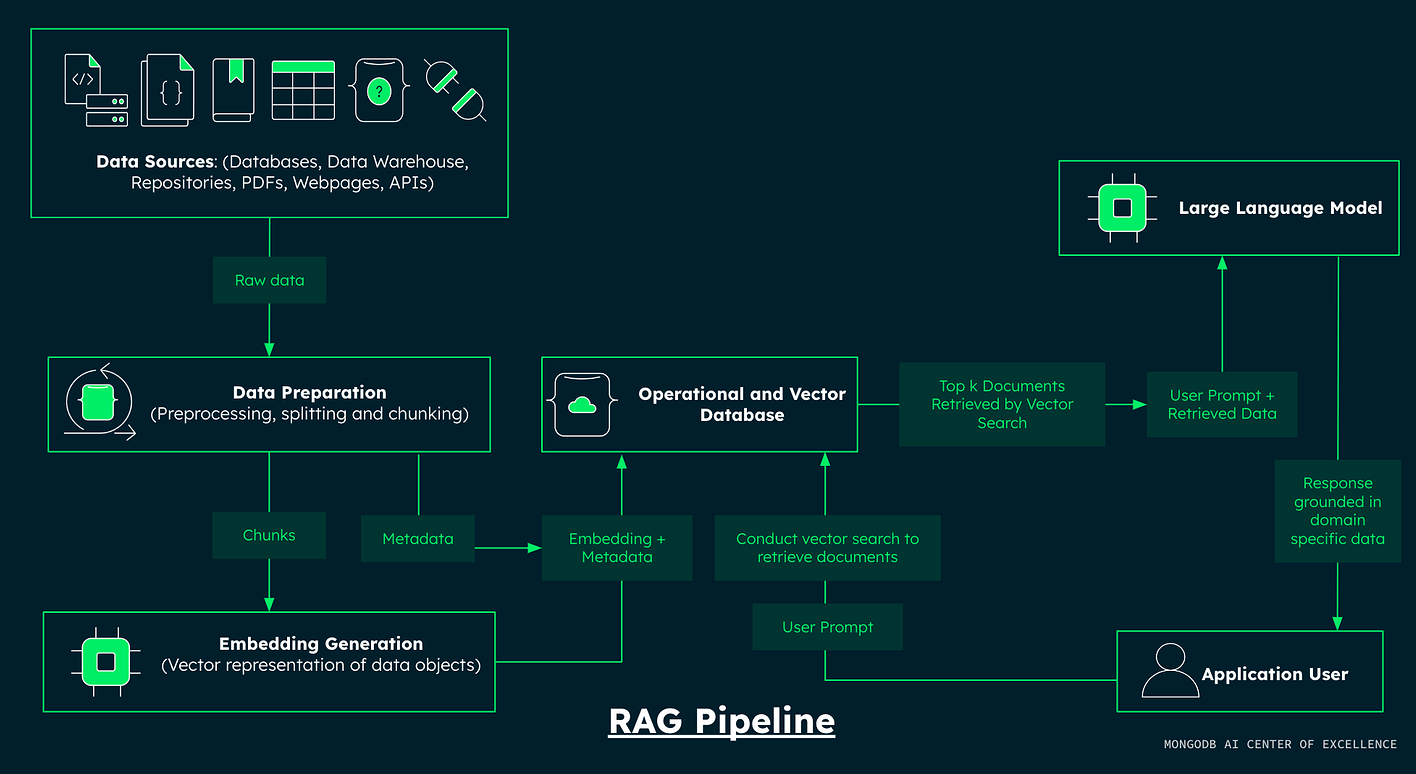
🏗️ System Architecture Overview
The system consists of three main components:
0. Pre-Read:
To follow along you will need
- Active Mongo DB Atlas account
- Ollama (with the model nomic-embed-text)
- A Gemini API key / Service Account Json
1. Generating Embeddings
We convert movie plot descriptions into numerical vectors using Ollama:
emb = ollama.embeddings(model="nomic-embed-text", prompt=doc["fullplot"])["embedding"]
These embeddings capture the semantic meaning of text, enabling similarity-based search.
2. Creating a Vector Search Index
MongoDB enables efficient similarity search using vector indexing:
{
"type": "vector",
"path": "embedding",
"numDimensions": dimensions,
"similarity": "cosine"
}
This allows us to quickly find movies with similar plots.
3. Building the Chat Application
Using Streamlit, we create an interactive chat interface:
- User enters a query
- Query is converted into an embedding
- MongoDB retrieves similar movie plots
- Gemini generates the final answer
Retrieval + Generation Flow
1. User asks:
"Suggest a movie about space and emotions"
2. System:
- Converts query into embedding
- Retrieves top similar plots
3. LLM (Gemini):
- Understands context
- Generates explanation
4. UI:
- Displays recommendations with reasoning
Why This Approach Works
Context-Aware Responses
The system uses real movie data instead of relying only on the model.
Scalable Architecture
Each component (DB, embeddings, LLM) can scale independently.
Flexible Design
You can swap:
- Gemini → OpenAI
- MongoDB → FAISS
- Ollama → HuggingFace
Real-World Applications
This architecture is not limited to movies. It can be used for:
- Enterprise knowledge assistants
- Document search systems
- Customer support chatbots
- Internal copilots
Key Takeaways
- Vector embeddings are crucial for semantic understanding
- RAG improves accuracy and reduces hallucination
- MongoDB simplifies vector search infrastructure
- Combining retrieval + LLM is the future of AI applications
Conclusion
By combining MongoDB, Ollama, and Gemini, we can build a powerful and scalable AI system that delivers intelligent recommendations. As AI continues to evolve, RAG-based architectures will become the foundation of next-generation applications — especially in enterprise automation and copilots.















Subscribe to our mailing list to get the new updates!

Subscribe our newsletter to stay updated