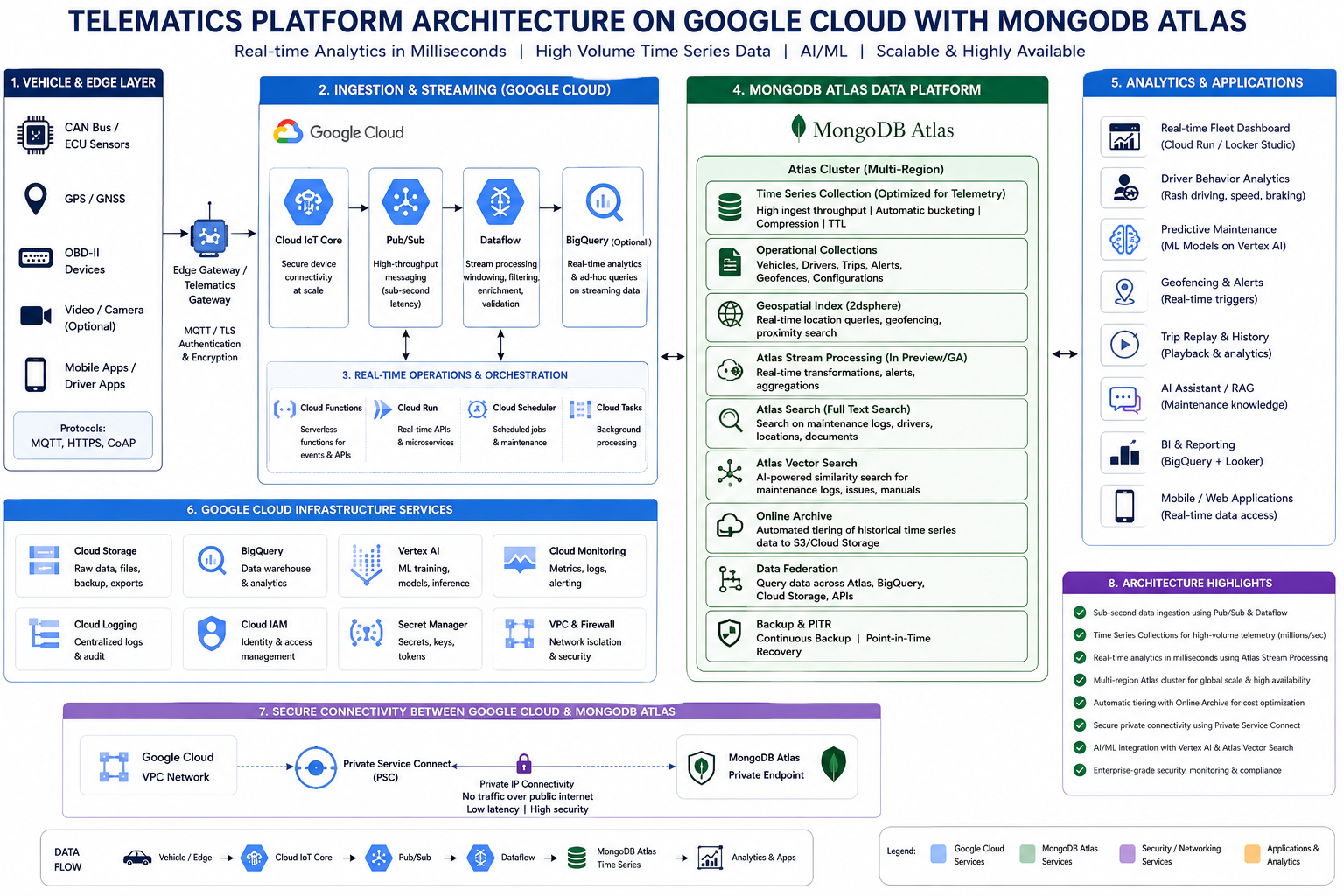
- Real Time Telematics Platform on MongoDB
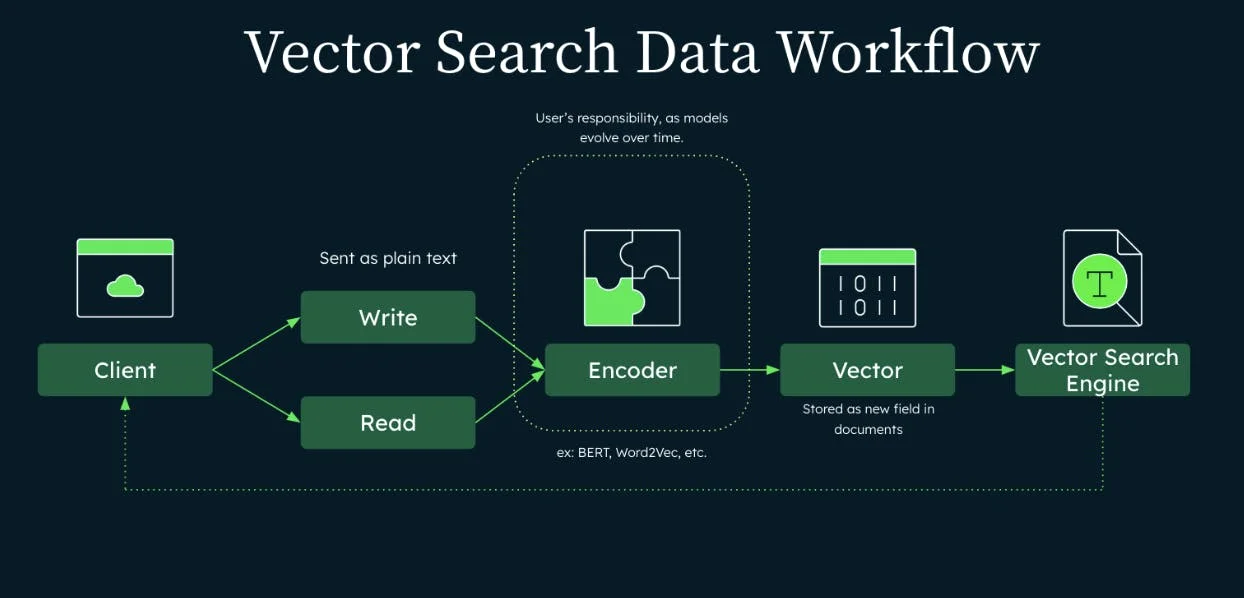
- MongoDB Zero Shot Semantic Serach
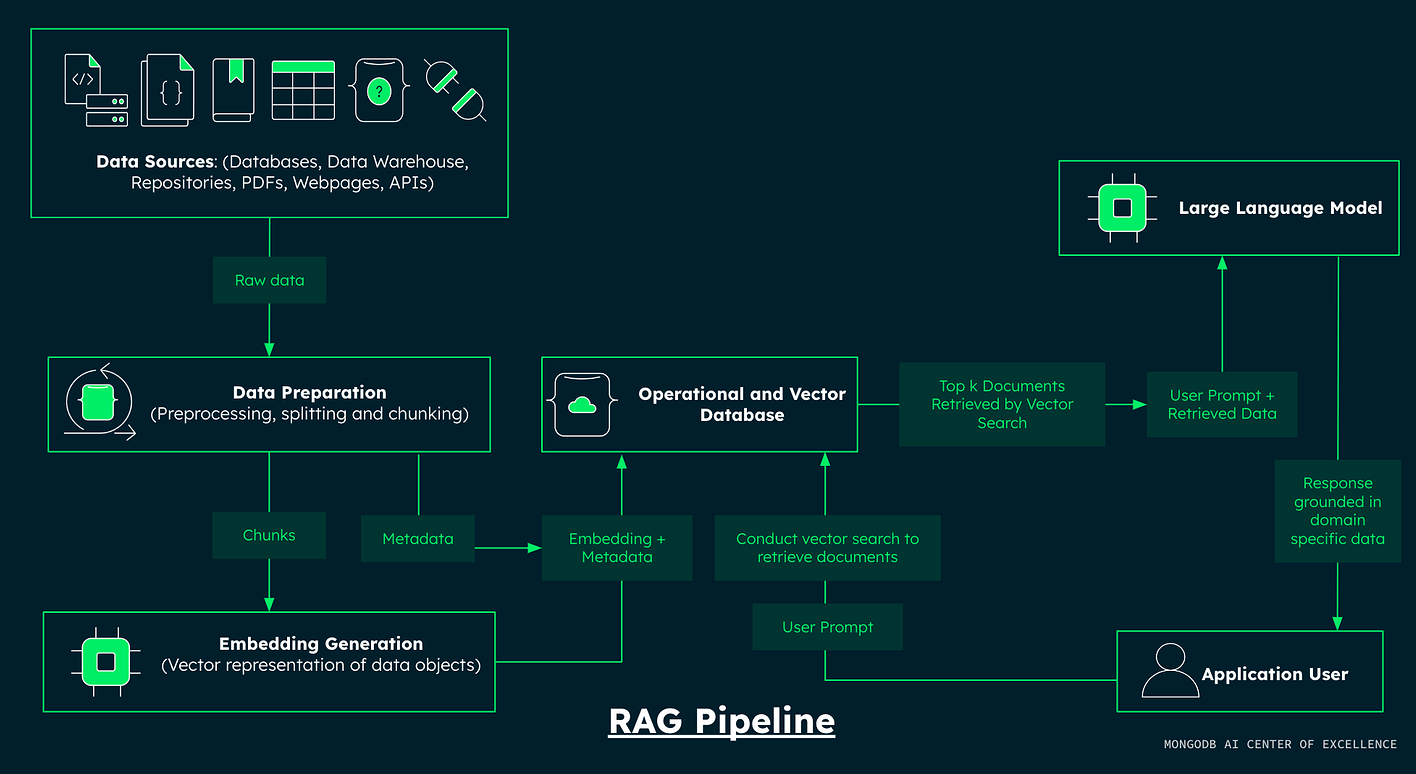
- Building an AI-Powered Recommendation System using RAG, MongoDB, Ollama, and Gemini
- AI Database Features
- Understanding Agentic AI: The Shift from Passive Models to Autonomous Agents
- The AI Blockchain
- Model Context Protocol (MCP) vs Agent to Agent (A2A) Protocol
- Responsible AI
- Building a CI/CD Pipeline for Machine Learning Using AWS Services
- DeepSeek Architecture
- Machine Learning for Beginners. Your roadmap to success.
- The Machine Learning Algorithms List: Types and Use Cases
- Harnessing Machine Learning for Advanced A/V Analysis and Detection
- TensorFlow Lite vs PyTorch Mobile for On-Device Machine Learning
- Generative AI presents new opportunities for accelerating human achievement
- Unlocking the true potential of AI with UiPath business automation
- AI for good: Three principles to use AI at work responsibly
- Transforming healthcare document processing with AI

Building a CI/CD Pipeline for Machine Learning Using AWS Services
In the world of Machine Learning (ML), deploying models into production is just as critical as building them. However, the process of developing, testing, and deploying ML models can be complex and error-prone if not managed properly. This is where Continuous Integration and Continuous Deployment (CI/CD) pipelines come into play. By automating the process, you can ensure that your ML models are deployed efficiently, reliably, and with minimal manual intervention.
In this blog, we’ll walk through how to build a CI/CD pipeline for ML using AWS services. We’ll cover the key components, tools, and steps involved in creating a robust pipeline that can handle the unique challenges of ML workflows.
Why CI/CD for Machine Learning?
Traditional software development CI/CD pipelines focus on code integration, testing, and deployment. However, ML pipelines have additional complexities, such as:
- Data Management: ML models depend on data, which can change over time.
- Model Training: Training is computationally expensive and time-consuming.
- Model Versioning: Models need to be versioned alongside code and data.
- Testing: ML models require specialized testing, such as accuracy and performance validation.
A well-designed CI/CD pipeline for ML addresses these challenges by automating data preprocessing, model training, testing, and deployment.
Key Components of an ML CI/CD Pipeline
- Source Control: Store your code, data, and model definitions in a version-controlled repository (e.g., AWS CodeCommit or GitHub).
- Data Pipeline: Automate data ingestion, preprocessing, and feature engineering.
- Model Training: Train models using scalable compute resources (e.g., AWS SageMaker).
- Model Testing: Validate model performance using automated tests.
- Model Deployment: Deploy models to production environments (e.g., SageMaker Endpoints).
- Monitoring: Continuously monitor model performance in production.
AWS Services for Building an ML CI/CD Pipeline
Here’s a list of AWS services that can be used to build an end-to-end CI/CD pipeline for ML:
- AWS CodePipeline: Orchestrates the CI/CD workflow.
- AWS CodeBuild: Builds and tests your ML code.
- AWS SageMaker: Handles data preprocessing, model training, and deployment.
- AWS Lambda: Runs serverless functions for automation tasks.
- AWS Step Functions: Coordinates multi-step workflows.
- Amazon S3: Stores datasets, model artifacts, and logs.
- Amazon CloudWatch: Monitors pipeline execution and model performance.
- AWS CloudFormation: Automates infrastructure provisioning.
Step-by-Step Guide to Building the Pipeline
Step 1: Set Up Version Control
- Use AWS CodeCommit or integrate with GitHub to store your ML code, data, and configuration files.
Organize your repository to separate code, data, and model artifacts.
Step 2: Automate Data Preprocessing
- Use AWS SageMaker Processing Jobs to preprocess data.
- Store raw and processed data in Amazon S3.
Trigger preprocessing jobs automatically when new data is uploaded.
Step 3: Train Models with SageMaker
- Use SageMaker Training Jobs to train your ML models.
- Define your training script, hyperparameters, and compute resources in a SageMaker-compatible format.
Store trained model artifacts in S3.
Step 4: Test Models
- Use AWS CodeBuild to run automated tests on your trained models.
- Validate model accuracy, performance, and compliance with business requirements.
If the model passes tests, proceed to deployment; otherwise, retrain or debug.
Step 5: Deploy Models
- Use SageMaker Endpoints to deploy your model for real-time inference.
- For batch inference, use SageMaker Batch Transform.
Implement canary deployments or A/B testing to ensure smooth rollouts.
Step 6: Monitor Model Performance
- Use Amazon CloudWatch to monitor endpoint metrics like latency, error rates, and invocation counts.
- Set up alerts for model drift or performance degradation.
Retrain models automatically if performance drops below a threshold.
Step 7: Orchestrate the Pipeline
- Use AWS CodePipeline to define the stages of your CI/CD pipeline (e.g., source, build, train, test, deploy).
Use AWS Step Functions to coordinate complex workflows, such as retraining and deployment.
Conclusion
Building a CI/CD pipeline for Machine Learning using AWS services can significantly streamline your ML workflows, reduce errors, and accelerate time-to-market. By leveraging tools like SageMaker, CodePipeline, and CloudWatch, you can create a robust, automated pipeline that handles everything from data preprocessing to model deployment and monitoring.
Whether you’re a data scientist, ML engineer, or DevOps professional, adopting CI/CD practices for ML will help you deliver high-quality models that drive real business value. Start small, iterate, and scale your pipeline as your ML needs grow.














Subscribe to our mailing list to get the new updates!

Subscribe our newsletter to stay updated