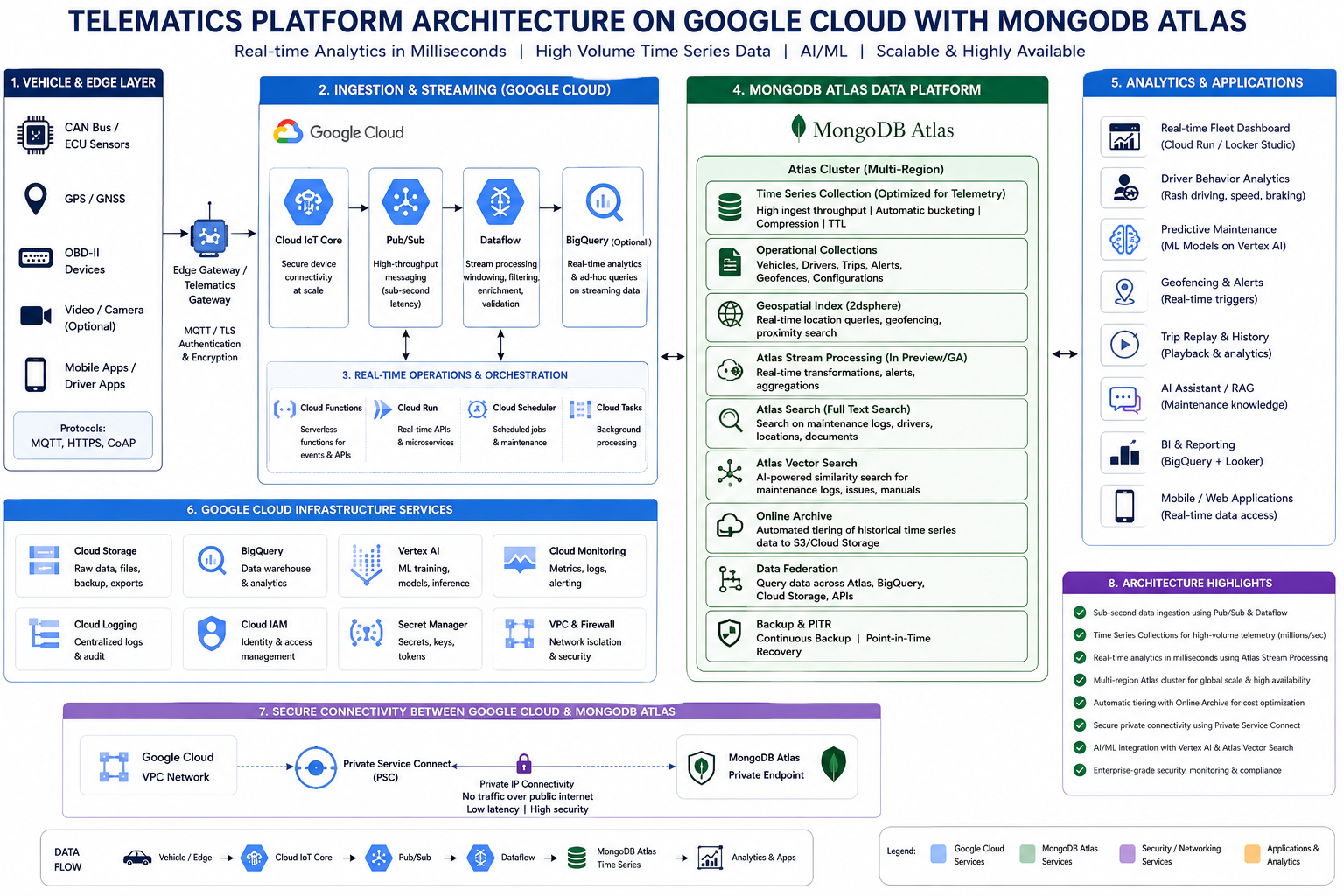
- Real Time Telematics Platform on MongoDB
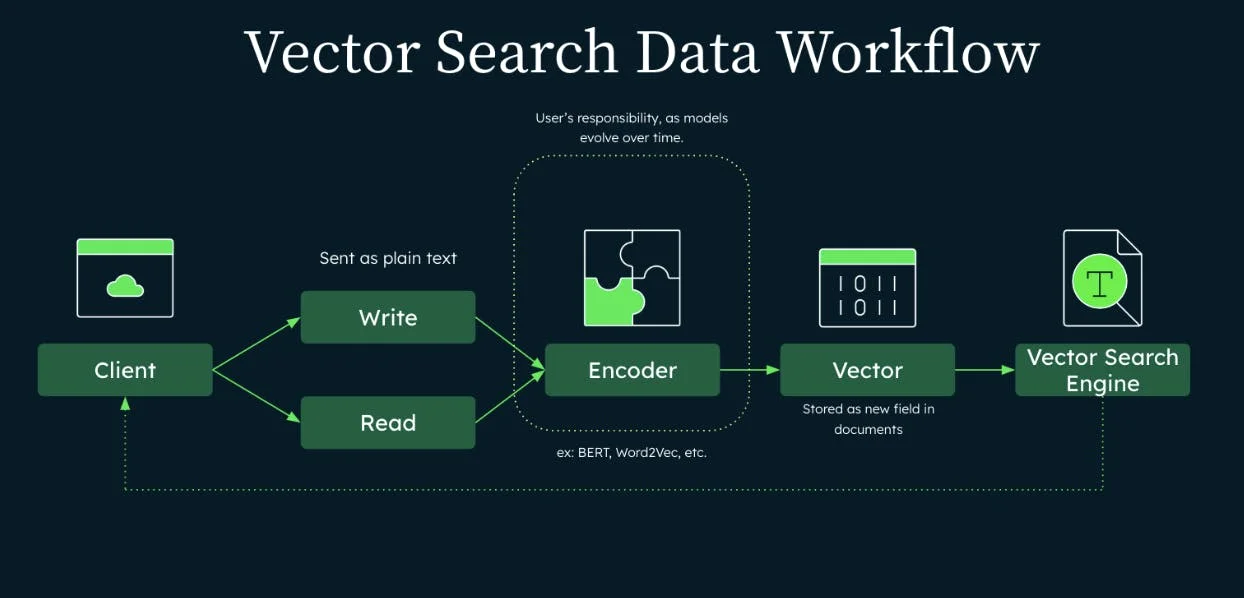
- MongoDB Zero Shot Semantic Serach
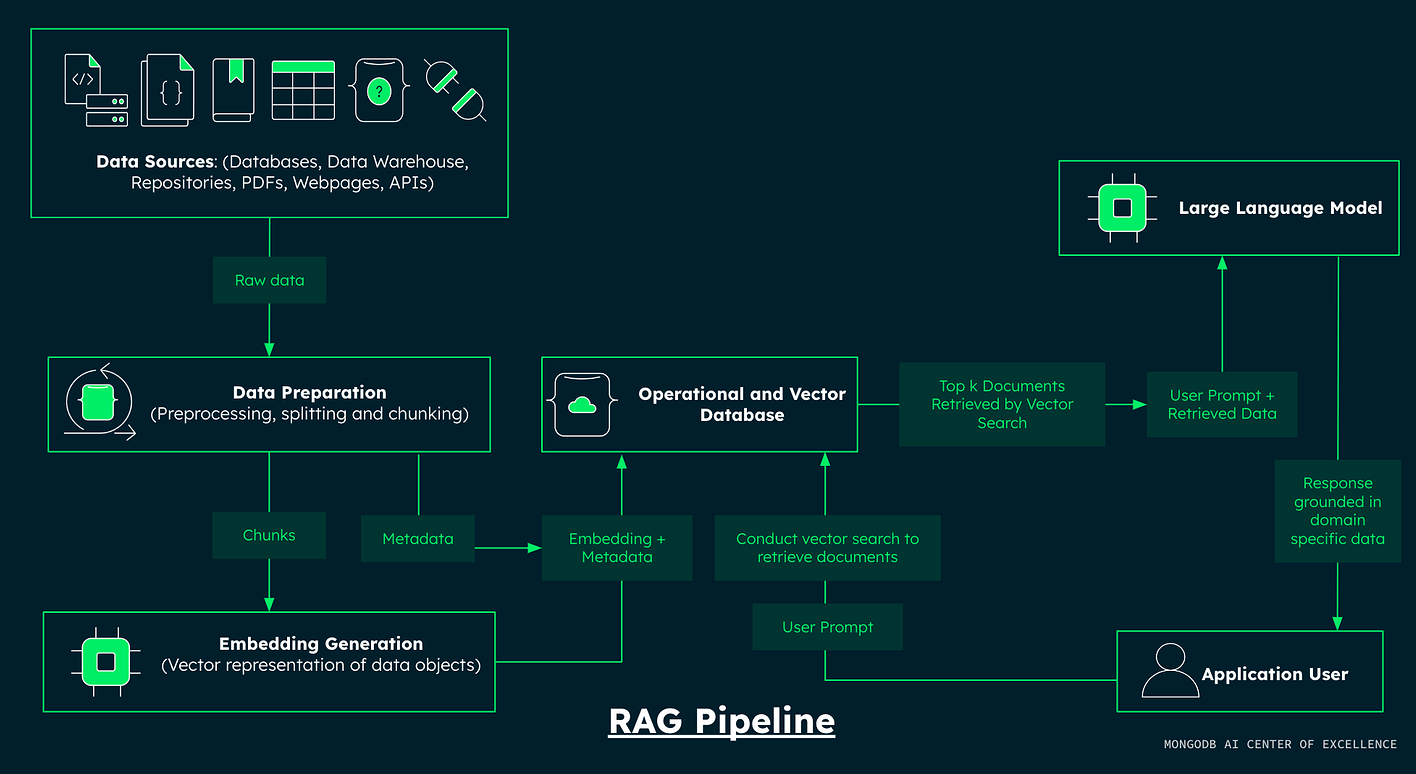
- Building an AI-Powered Recommendation System using RAG, MongoDB, Ollama, and Gemini
- AI Database Features
- Understanding Agentic AI: The Shift from Passive Models to Autonomous Agents
- The AI Blockchain
- Model Context Protocol (MCP) vs Agent to Agent (A2A) Protocol
- Responsible AI
- Building a CI/CD Pipeline for Machine Learning Using AWS Services
- DeepSeek Architecture
- Machine Learning for Beginners. Your roadmap to success.
- The Machine Learning Algorithms List: Types and Use Cases
- Harnessing Machine Learning for Advanced A/V Analysis and Detection
- TensorFlow Lite vs PyTorch Mobile for On-Device Machine Learning
- Generative AI presents new opportunities for accelerating human achievement
- Unlocking the true potential of AI with UiPath business automation
- AI for good: Three principles to use AI at work responsibly
- Transforming healthcare document processing with AI

The Machine Learning Algorithms List: Types and Use Cases
The Machine Learning Algorithms List: Types and Use Cases

In a world where nearly all manual tasks are being automated, the definition of manual is changing. There are now many different types of Machine Learning algorithms, some of which can help computers play chess, perform surgeries, and get smarter and more personal. We are living in an era of constant technological progress, and looking at how computing has advanced over the years, we can predict what’s to come in the days ahead.
In the fast-evolving field of machine learning, understanding the right algorithms is crucial for any aspiring engineer or data scientist. This article highlights the top 10 machine learning algorithms that every machine learning engineer should be familiar with to build effective models and derive meaningful insights from data.
Top 10 Machine Learning Algorithms?
Below is the list of the top 10 commonly used Machine Learning Algorithms:
- Linear regression
- Logistic regression
- Decision tree
- SVM algorithm
- Naive Bayes algorithm
- KNN algorithm
- K-means
- Random forest algorithm
- Dimensionality reduction algorithms
- Gradient boosting algorithm and AdaBoosting algorithm
Become a AI & Machine Learning Professional
- $267 billionExpected global AI market value by 2027
- 37.3%Projected CAGR of the global AI market from 2023-2030
- $15.7 trillionExpected total contribution of AI to the global economy by 2030
Post Graduate Program in AI and Machine Learning
- Program completion certificate from Purdue University and Simplilearn
- Gain exposure to ChatGPT, OpenAI, Dall-E, Midjourney & other prominent tools
11 months
View Program
Artificial Intelligence Engineer
- Industry-recognized AI Engineer Master’s certificate from Simplilearn
- Dedicated live sessions by faculty of industry experts
11 Months
View Program
Here's what learners are saying regarding our programs:

Akili Yang
Personal Financial Consultant, OCBC Bank
The live sessions were quite good; you could ask questions and clear doubts. Also, the self-paced videos can be played conveniently, and any course part can be revisited. The hands-on projects were also perfect for practice; we could use the knowledge we acquired while doing the projects and apply it in real life.

Indrakala Nigam Beniwal
Technical Consultant, Land Transport Authority (LTA) Singapore
I completed a Master's Program in Artificial Intelligence Engineer with flying colors from Simplilearn. Thanks to the course teachers and others associated with designing such a wonderful learning experience.
Not sure what you’re looking for?
Types of Machine Learning Algorithms
1. Supervised Learning
Supervised learning algorithms are trained using labeled data, which means the input data is tagged with the correct output. The goal of these algorithms is to learn a mapping from inputs to outputs, making it possible to predict the output for new data. Common supervised learning algorithms include:
- Linear Regression: Used for predicting continuous outcomes. It models the relationship between a dependent variable and one or more independent variables by fitting a linear equation to observed data.
- Logistic Regression: Used for binary classification tasks (e.g., predicting yes/no outcomes). It estimates probabilities using a logistic function.
- Decision Trees: These models predict the value of a target variable by learning simple decision rules inferred from the data features.
- Random Forests: An ensemble of decision trees, typically used for classification and regression, improving model accuracy and overfitting control.
- Support Vector Machines (SVM): Effective in high-dimensional spaces, SVM is primarily used for classification but can also be used for regression.
- Neural Networks: These are powerful models that can capture complex non-linear relationships. They are widely used in deep learning applications.
2. Unsupervised Learning
Unsupervised learning algorithms are used with data sets without labeled responses. The goal here is to infer the natural structure present within a set of data points. Common unsupervised learning techniques include:
- Clustering: Algorithms like K-means, hierarchical clustering, and DBSCAN group a set of objects in such a way that objects in the same group are more similar to each other than to those in other groups.
- Association: These algorithms find rules that describe large portions of your data, such as market basket analysis.
- Principal Component Analysis (PCA): A statistical procedure that uses an orthogonal transformation to convert a set of observations of possibly correlated variables into a set of values of linearly uncorrelated variables.
- Autoencoders: Special type of neural network used to learn efficient codings of unlabeled data.
3. Reinforcement Learning
algorithms learn to make a sequence of decisions. The algorithm learns to achieve a goal in an uncertain, potentially complex environment. In reinforcement learning, an agent makes decisions by following a policy based on which actions to take, and it learns from the consequences of these actions through rewards or penalties.
- Q-learning: This is a model-free reinforcement learning algorithm that learns the value of an action in a particular state.
- Deep Q-Networks (DQN): It combines Q-learning with deep neural networks, allowing the approach to learn successful policies directly from high-dimensional sensory inputs.
- Policy Gradient Methods: These methods optimize the parameters of a policy directly as opposed to estimating the value of actions.
- Monte Carlo Tree Search (MCTS): Used in decision processes for finding optimal decisions by playing out scenarios, notably used in games like Go.
These categories provide a broad overview of the most common types of machine learning algorithms. Each has its strengths and ideal use cases, making them better suited for certain types of tasks over others.
Become a AI & Machine Learning Professional
- $267 billionExpected global AI market value by 2027
- 37.3%Projected CAGR of the global AI market from 2023-2030
- $15.7 trillionExpected total contribution of AI to the global economy by 2030
Post Graduate Program in AI and Machine Learning
- Program completion certificate from Purdue University and Simplilearn
- Gain exposure to ChatGPT, OpenAI, Dall-E, Midjourney & other prominent tools
11 months
Artificial Intelligence Engineer
- Industry-recognized AI Engineer Master’s certificate from Simplilearn
- Dedicated live sessions by faculty of industry experts
11 Months
Here's what learners are saying regarding our programs:
Akili Yang
Personal Financial Consultant, OCBC Bank
The live sessions were quite good; you could ask questions and clear doubts. Also, the self-paced videos can be played conveniently, and any course part can be revisited. The hands-on projects were also perfect for practice; we could use the knowledge we acquired while doing the projects and apply it in real life.
Indrakala Nigam Beniwal
Technical Consultant, Land Transport Authority (LTA) Singapore
I completed a Master's Program in Artificial Intelligence Engineer with flying colors from Simplilearn. Thanks to the course teachers and others associated with designing such a wonderful learning experience.
Not sure what you’re looking for?
List of Popular Machine Learning Algorithms
1. Linear Regression
To understand the working functionality of Linear Regression, imagine how you would arrange random logs of wood in increasing order of their weight. There is a catch; however – you cannot weigh each log. You have to guess its weight just by looking at the height and girth of the log (visual analysis) and arranging them using a combination of these visible parameters. This is what linear regression in machine learning is like.
In this process, a relationship is established between independent and dependent variables by fitting them to a line. This line is known as the regression line and is represented by a linear equation Y= a *X + b.
In this equation:
- Y – Dependent Variable
- a – Slope
- X – Independent variable
- b – Intercept
The coefficients a & b are derived by minimizing the sum of the squared difference of distance between data points and the regression line.
2. Logistic Regression
Logistic Regression is used to estimate discrete values (usually binary values like 0/1) from a set of independent variables. It helps predict the probability of an event by fitting data to a logit function. It is also called logit regression.
These methods listed below are often used to help improve logistic regression models:
- include interaction terms
- eliminate features
- regularize techniques
- use a non-linear model
3. Decision Tree
Decision Tree algorithm in machine learning is one of the most popular algorithm in use today; this is a supervised learning algorithm that is used for classifying problems. It works well in classifying both categorical and continuous dependent variables. This algorithm divides the population into two or more homogeneous sets based on the most significant attributes/ independent variables.
4. SVM (Support Vector Machine) Algorithm
SVM algorithm is a method of a classification algorithm in which you plot raw data as points in an n-dimensional space (where n is the number of features you have). The value of each feature is then tied to a particular coordinate, making it easy to classify the data. Lines called classifiers can be used to split the data and plot them on a graph.
5. Naive Bayes Algorithm
A Naive Bayes classifier assumes that the presence of a particular feature in a class is unrelated to the presence of any other feature.
Even if these features are related to each other, a Naive Bayes classifier would consider all of these properties independently when calculating the probability of a particular outcome.
A Naive Bayesian model is easy to build and useful for massive datasets. It's simple and is known to outperform even highly sophisticated classification methods.
6. KNN (K- Nearest Neighbors) Algorithm
This algorithm can be applied to both classification and regression problems. Apparently, within the Data Science industry, it's more widely used to solve classification problems. It’s a simple algorithm that stores all available cases and classifies any new cases by taking a majority vote of its k neighbors. The case is then assigned to the class with which it has the most in common. A distance function performs this measurement.
KNN can be easily understood by comparing it to real life. For example, if you want information about a person, it makes sense to talk to his or her friends and colleagues!
Things to consider before selecting K Nearest Neighbours Algorithm:
- KNN is computationally expensive
- Variables should be normalized, or else higher range variables can bias the algorithm
- Data still needs to be pre-processed.
7. K-Means
It is an unsupervised learning algorithm that solves clustering problems. Data sets are classified into a particular number of clusters (let's call that number K) in such a way that all the data points within a cluster are homogenous and heterogeneous from the data in other clusters.
How K-means forms clusters:
- The K-means algorithm picks k number of points, called centroids, for each cluster.
- Each data point forms a cluster with the closest centroids, i.e., K clusters.
- It now creates new centroids based on the existing cluster members.
- With these new centroids, the closest distance for each data point is determined. This process is repeated until the centroids do not change.
Become a AI & Machine Learning Professional
- $267 billionExpected global AI market value by 2027
- 37.3%Projected CAGR of the global AI market from 2023-2030
- $15.7 trillionExpected total contribution of AI to the global economy by 2030
Post Graduate Program in AI and Machine Learning
- Program completion certificate from Purdue University and Simplilearn
- Gain exposure to ChatGPT, OpenAI, Dall-E, Midjourney & other prominent tools
11 months
View Program
Artificial Intelligence Engineer
- Industry-recognized AI Engineer Master’s certificate from Simplilearn
- Dedicated live sessions by faculty of industry experts
11 Months
View Program
Here's what learners are saying regarding our programs:
Akili Yang
Personal Financial Consultant, OCBC Bank
The live sessions were quite good; you could ask questions and clear doubts. Also, the self-paced videos can be played conveniently, and any course part can be revisited. The hands-on projects were also perfect for practice; we could use the knowledge we acquired while doing the projects and apply it in real life.
Indrakala Nigam Beniwal
Technical Consultant, Land Transport Authority (LTA) Singapore
I completed a Master's Program in Artificial Intelligence Engineer with flying colors from Simplilearn. Thanks to the course teachers and others associated with designing such a wonderful learning experience.
Not sure what you’re looking for?
8. Random Forest Algorithm
A collective of decision trees is called a Random Forest. To classify a new object based on its attributes, each tree is classified, and the tree “votes” for that class. The forest chooses the classification having the most votes (over all the trees in the forest).
Each tree is planted & grown as follows:
- If the number of cases in the training set is N, then a sample of N cases is taken at random. This sample will be the training set for growing the tree.
- If there are M input variables, a number m<<M is specified such that at each node, m variables are selected at random out of the M, and the best split on this m is used to split the node. The value of m is held constant during this process.
- Each tree is grown to the most substantial extent possible. There is no pruning.
9. Dimensionality Reduction Algorithms
In today's world, vast amounts of data are being stored and analyzed by corporates, government agencies, and research organizations. As a data scientist, you know that this raw data contains a lot of information - the challenge is to identify significant patterns and variables.
Dimensionality reduction algorithms like Decision Tree, Factor Analysis, Missing Value Ratio, and Random Forest can help you find relevant details.
10. Gradient Boosting Algorithm and AdaBoosting Algorithm
Gradient Boosting Algorithm and AdaBoosting Algorithm are boosting algorithms used when massive loads of data have to be handled to make predictions with high accuracy. Boosting is an ensemble learning algorithm that combines the predictive power of several base estimators to improve robustness.
In short, it combines multiple weak or average predictors to build a strong predictor. These boosting algorithms always work well in data science competitions like Kaggle, AV Hackathon, CrowdAnalytix. These are the most preferred machine learning algorithms today. Use them, along with Python and R Codes, to achieve accurate outcomes.
You can also watch our in-demand video on top Machine Learning Algorithms.
Supervised vs. Unsupervised vs. Reinforcement Learning Algorithms
Let’s look at how supervised, unsupervised, and reinforcement learning really stack up across a few key areas.
Data Labeling
In supervised learning, you have labeled data at your disposal, meaning the answers are already known for each example, making it easier to train the model. Unsupervised learning, on the other hand, doesn’t come with labels, so the algorithm has to figure out patterns on its own. Reinforcement learning also skips labeled data; instead, it learns by taking actions, getting feedback through rewards or penalties, and using that feedback to keep improving.
Goal Orientation
Supervised learning has a clear goal in mind; you’re trying to predict specific outcomes using labeled data. Unsupervised learning isn’t as structured; it’s more about exploring the data to uncover hidden patterns or clusters. With reinforcement learning, the goal is all about maximizing rewards over time, adjusting actions based on past mistakes and successes to do better as it goes along.
Learning Approach
In supervised learning, it involves giving the model numerous examples with a known result and the model is trained to achieve the results through such examples. Unsupervised learning takes the algorithm in a different role: discovering structure within the data. For example, finding clusters or associations. Reinforcement learning in its approach is relatively different, it is more fluid in that it evolves through interacting with the environment and learning as it progresses through its strategy.
Application Scenarios
Supervised learning is best suited for tasks such as outcome forecasting and pattern recognition. It involves classification and prediction. On the other hand, unsupervised learning is most useful in identifying groups within the data, detecting outliers, or reducing the dimensionality of the data. Reinforcement learning is particularly useful in areas where real-time decisions are required such as robotics, games, etc. in which performance can be enhanced through experience.
Become a AI & Machine Learning Professional
- $267 billionExpected global AI market value by 2027
- 37.3%Projected CAGR of the global AI market from 2023-2030
- $15.7 trillionExpected total contribution of AI to the global economy by 2030
Post Graduate Program in AI and Machine Learning
- Program completion certificate from Purdue University and Simplilearn
- Gain exposure to ChatGPT, OpenAI, Dall-E, Midjourney & other prominent tools
11 months
View Program
Artificial Intelligence Engineer
- Industry-recognized AI Engineer Master’s certificate from Simplilearn
- Dedicated live sessions by faculty of industry experts
11 Months
View Program
Here's what learners are saying regarding our programs:
Akili Yang
Personal Financial Consultant, OCBC Bank
The live sessions were quite good; you could ask questions and clear doubts. Also, the self-paced videos can be played conveniently, and any course part can be revisited. The hands-on projects were also perfect for practice; we could use the knowledge we acquired while doing the projects and apply it in real life.
Indrakala Nigam Beniwal
Technical Consultant, Land Transport Authority (LTA) Singapore
I completed a Master's Program in Artificial Intelligence Engineer with flying colors from Simplilearn. Thanks to the course teachers and others associated with designing such a wonderful learning experience.
Not sure what you’re looking for?
When to Use Supervised, Unsupervised, or Reinforcement Learning
Supervised learning works best when labeled data is readily available, and you need precise predictions. It’s often used in spam detection, stock price prediction, and medical diagnosis.
Unsupervised learning is great when exploring new data to find patterns or clusters, such as customer segmentation or anomaly detection.
Reinforcement learning is suitable for scenarios involving continuous learning, like training a robot to navigate or optimizing game strategies, where feedback is given over time.
Factors to Consider When Choosing a Machine Learning Algorithm
Let’s explore what to consider when making choosing a machine learning algorithm:
Type of Data
The first thing to look at is determining the type of data that you have. For instance, labeled datasets or those with defined outputs can be entrusted in the hands of supervised methods. On the other hand, in the case of unlabeled data, unsupervised approaches are required to locate hidden structures. In scenarios where learning is carried out through interactions, reinforcement learning seems to be a useful candidate.
Complexity of the Problem
After that, evaluate the complexity of the problem you are trying to solve. In tasks that are less complex, simpler algorithms can do the job. However, if you’re tackling a more complex issue with intricate relationships, you might want to use more advanced methods, like neural networks or ensemble techniques. Just be prepared for a bit more effort and tuning.
Computational Resources
Another important factor is the computational power at your disposal. Some algorithms, like deep learning models, can be resource-intensive and require powerful hardware. If you're working with limited resources, simpler algorithms like logistic regression or k-nearest neighbors can still deliver solid results without putting too much strain on your system.
Interpretability vs. Accuracy
Finally, think about whether you need an algorithm that’s easy to understand or one that prioritizes accuracy, even if it’s a bit of a black box. Decision trees and linear regression are generally easier to interpret, making them great for explaining to stakeholders. In contrast, more complex models like neural networks might give you better accuracy but can be harder to explain.
Become a AI & Machine Learning Professional
- $267 billionExpected global AI market value by 2027
- 37.3%Projected CAGR of the global AI market from 2023-2030
- $15.7 trillionExpected total contribution of AI to the global economy by 2030
Post Graduate Program in AI and Machine Learning
- Program completion certificate from Purdue University and Simplilearn
- Gain exposure to ChatGPT, OpenAI, Dall-E, Midjourney & other prominent tools
11 months
View Program
Artificial Intelligence Engineer
- Industry-recognized AI Engineer Master’s certificate from Simplilearn
- Dedicated live sessions by faculty of industry experts
11 Months
View Program
Here's what learners are saying regarding our programs:
Akili Yang
Personal Financial Consultant, OCBC Bank
The live sessions were quite good; you could ask questions and clear doubts. Also, the self-paced videos can be played conveniently, and any course part can be revisited. The hands-on projects were also perfect for practice; we could use the knowledge we acquired while doing the projects and apply it in real life.
Indrakala Nigam Beniwal
Technical Consultant, Land Transport Authority (LTA) Singapore
I completed a Master's Program in Artificial Intelligence Engineer with flying colors from Simplilearn. Thanks to the course teachers and others associated with designing such a wonderful learning experience.
Not sure what you’re looking for?View all Related Programs
Conclusion
IMastering these Machine Learning Algorithms are a great way to build a career in machine learning. The field is proliferating, and the sooner you understand the scope of machine learning tools, the sooner you'll be able to provide solutions to complex work problems.
However, if you are experienced in the field and want to boost your career, you can take-up the Post Graduate Program in AI and Machine Learning in partnership with Purdue University collaborated with IBM. This program gives you an in-depth knowledge of Python, Deep Learning algorithm with the Tensor flow, Natural Language Processing, Speech Recognition, Computer Vision, and Reinforcement Learning. Explore and enroll today!

FAQs
1. What is an algorithm in machine learning?
Algorithms in machine learning are mathematical procedures and techniques that allow computers to learn from data, identify patterns, make predictions, or perform tasks without explicit programming. These algorithms can be categorized into various types, such as supervised learning, unsupervised learning, reinforcement learning, and more.
2. What are the three types of machine learning algorithms?
The three basic machine learning algorithms are:
- Supervised Learning: Algorithms learn from labeled data to make predictions or classify new data.
- Unsupervised Learning: Algorithms analyze unlabeled data to discover patterns, group similar data, or reduce dimensions.
- Reinforcement Learning: Here, algorithms learn through trial and error by interacting with an environment to maximize rewards.
3. What are the 4 machine learning algorithm?
The 4 machine learning algorithms are:
- Supervised Algorithm
- Unsupervised Algorithm
- Semi-Supervised Algorithm
- Reinforcement Algorithm
4. Which ML algorithm is best for prediction?
The best ML algorithm for prediction depends on variety of factors such as the nature of the problem, the type of data, and the specific requirements. Popular algorithms for prediction tasks include Support Vector Machines, Random Forests, and Gradient Boosting methods. However, the choice of an algorithm should be based on experimentation and evaluation of the specific problem and dataset at hand.
5. What is the difference between supervised and unsupervised learning algorithms?
The primary difference between supervised and unsupervised learning lies in the type of data used for training. Supervised learning algorithms use labeled data, where the target output is known, to learn patterns and make predictions. Unsupervised learning algorithms work with unlabeled data, relying on intrinsic patterns and relationships to group data points or discover hidden structures.
6. Is CNN a machine learning algorithm?
A convolutional neural network (CNN or convnet) is a type of artificial neural network used for various tasks, especially with images and videos. It's a part of machine learning and works with different kinds of data.
Our AI & ML Courses Duration And Fees
AI & Machine Learning Courses typically range from a few weeks to several months, with fees varying based on program and














Subscribe to our mailing list to get the new updates!

Subscribe our newsletter to stay updated